Processing
📌 Article pinned by VulDB Support Team
The following diagram illustrates the work done 24/7 by our different moderation teams and international vulnerability analysts.
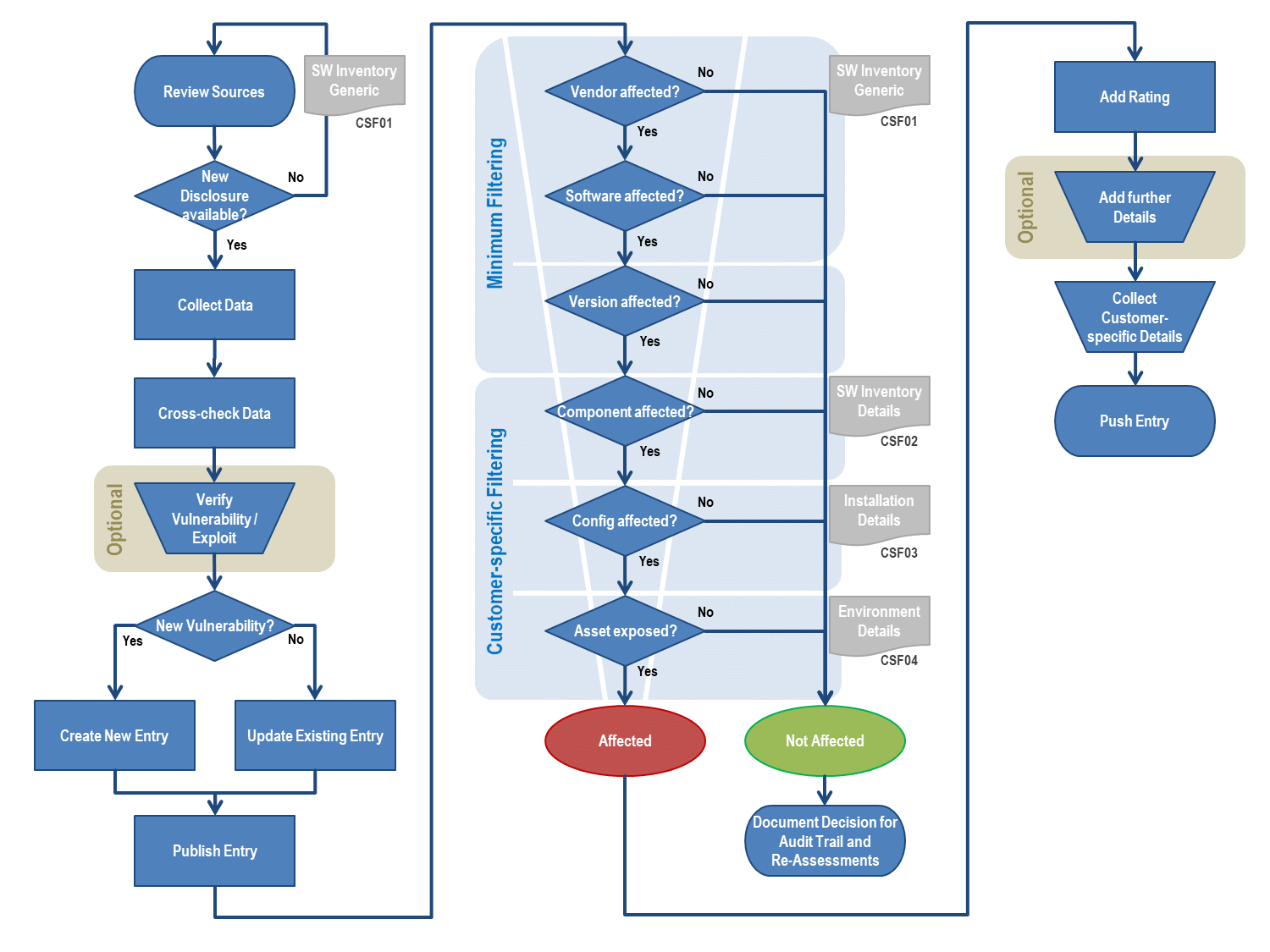
The vulnerability management processing is divided into 3 different streams:
Step1: Data Collection and Adding
The analysts at VulDB are reviewing multiple sources on a regular basis. This includes automated and manual review of different data. We divide between several classes of sources.
The initial task of the analysts is to determine whether there is a new disclosure available. If this is the case, the details about the possible issue are collected and cross-checked with other sources. This helps to increase the confidence of a new entry.
The collected data is compared to the existing data available in VulDB and other vulnerability sources (e.g. CVE). This shall prevent duplicate entries of existing issues, false-positives, obsolete or deleted entries.
If the issue appears to be new and is in accordance with our submission policy, it will be added as a new entry to the database. If the entry is eligeble for a CVE assignment, our CNA team will reserve such and push it into the official CVE stream.
If it is not a new entry but provides new details about an old entry, the existing entry will get updated. After adding the new data to the database, the entry gets peer-reviewed and published.
Step 2: Customer-related Filtering
Commercial customers subscribing to the alert service get additional processing of their entries. This is called the filtering stage. The goal is to streamline the results to provide the highest accuracy without flooding with noisy details. The simple filtering attributes are:
- Vendor Name [CSF01]
- Software Name [CSF01]
- Software Version [CSF01]
- Component Name [CSF02]
- Config Prerequisites [CSF03]
- Asset Exposure (topological context) [CSF04]
Synchronization between the analysis team and the customer is suggested whenever a software change is approaching. Status meeting every few weeks is a good way to keep the exchange between the experts flowing. To keep the desired quality on an high level, it is required to update the customer-specific details on a regular basis. This includes:
- Software details (vendor, name, version, components)
- Installation details (host configuration)
- Environment details (network architecture, topology, routing, firewalling, etc.)
Step 3: Additional Quality Assurance
The desire within high-security environments is higher than usual. This makes it a requirement to provide additional analysis and details about an entry.
Enterprise customers are able to define such high value targets which will initiate further technical analysis of the applicable issues. This will also result in a highly customer-specific risk rating and scenario analysis for these entries.
In some cases it is even possible to re-create the target environment in a lab to determine whether a public exploit is successful or not. It is even possible to modify a disclosed exploit or to create a new one from scratch to determine the real capabilities of a high-level attacker. This guarantees the highest level of quality.
Actualizaciones: 2024-05-26