Splitting
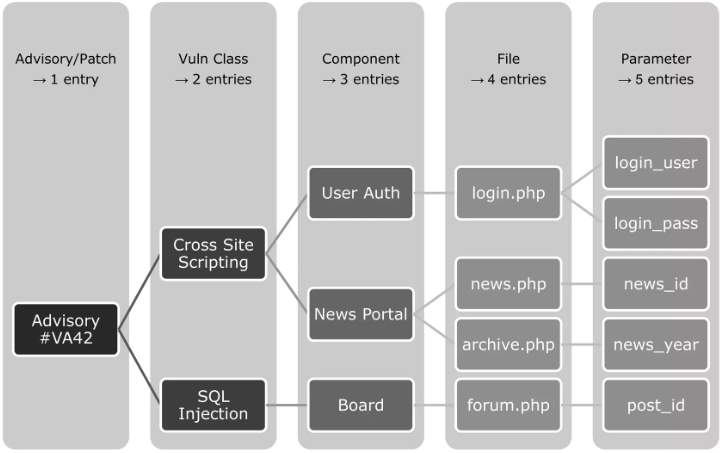
There are different methodologies in regards of splitting entries. Some sources create a single entry even for full patchdays (affecting multiple products), others are dividing as soon as there are multiple arguments affected (to create as many entries as possible to boost their stats). We chose something in between. According to the illustration we will chose the 4th approach which will cause four separate vulnerability entries.
Split
We have various factors which affect the decision to split into multiple vulnerability entries:
- Different Vulnerability Class: A very strong possibility to distinguish vulnerabilities from each other is the applied vulnerability class which is usually shown as a CWE value (Common Weakness Enumeration). For example, if the same product, file name, function, and argument is affected, but one issue is a Cross Site Scripting (CWE-79) and the other is an SQL Injection (CWE-89), we will create two seperate and independent vulnerability entries.
- Different Features Affected: If different features are affected, even by the same vulnerability class, we will create dedicated entries. For example this is true if the file
show_thread.phphas a Cross Site Scripting in the argumentidand the fileshow_user.phphas also a Cross Site Scripting in the argumentid. These are two separate features (show a forum thread and show an user profile) even though the same naming convention for the parameter is used. - Very Different Products: If two very different products are affected, especially when they do not share any codebase, we will create two separate entries. This makes it easier to associate entries with affected products. However, if a very general vulnerability affects multiple products, this could be an issue in a crypto protocol, then we might merge multiple products in one entry. In such cases the affected products are often listen in the data field
software_affected. - Similar Product but Too Different: Sometimes even very similar products might have enough differences. For example our binary analysis has shown that Microsoft Internet Explorer and Microsoft Edge entries shall be divided as they have severe differences. Therefore, even if Microsoft published a single advisory or CVE, we have created two separate entries. This would basically duplicate the base data of an entry. Typically the vulnerability class, access vector and advisory details. But there are other fields which might have important differences like CVSS (e.g. Windows versions have often different CVSS according to Microsoft), exploit prices (product dependency), patch details (e.g. IDs and links), vulnerability scanner plugins (different platforms), all threat intelligence data, etc.
Merge
There are also reasons when we do not create a separate entry but treat vulnerabilities like duplicates of existing entries:
- Very Same Duplicate: A duplicate which is the very same vulnerability of an existing vulnerability entry.
- Same Issue in Different Versions: If a vulnerability is associated with a specific version of a product and it remains vulnerable in a later version, we will not create a new entry and we will also not associate a different CVE. Instead we will merge the new information into the existing entry as an update.
- Similar Arguments of Same Feature: If a product provides as specific view and multiple functions, fields or arguments are affected by the same vulnerability (e.g. Cross Site Scripting), we will create one entry listing all the affected functions, fields or arguments.
- Different Attack Scenarios: Some attacks can be exploited within different attack scenarios. For example an attack might be exploited remote and local as well but has different pre-requisites. We do not create separate entries for such scenarios but will follow our CVSS principles to create the most reasonable entry.
- Vulnerability Class Chaining: Some attacks allow a chaining of vulnerability classes. For example an attacker might be able to exploit an SQL injection to affect data base queries (CWE-89). But this would also allow to circumvent an authentication (CWE-287) and read data from the affected database (CWE-200). In this case the initial vulnerability - the SQLi - will be the only entry. Under certain circumstances we will show such chaining in the CWE data.
Related Entries
Related vulnerability entries can be shown in the Relate View. The Vulnerability API data field source_seealso might inform you about entries which are connected with an entry as well.
已更新: 2024-06-16